Is there any increase in discussion related to data privacy in the danish parliament?
Peyman Kor
2020-07-22
Source:vignettes/myvignette.Rmd
myvignette.RmdIntroduction
So in this blog I going to explore and possible answer these two questions:
Is there any increase in sentiment of the members of the Danish parliament on the topics related to datatilsynet,persondata,persondataloven,databeskyttelse in the parliament discussion?
Then, which parties are more involved in the parliament about the above topics?
So, let’s get started:
Installing the danparcorpR package
First, we need to install the danparcorpR pacakge. To install this package first you need to install the remotes package. So first run this:
if(!require(remotes)){ install.packages("remotes") library(remotes) } #> Loading required package: remotes
The above package makes that you can install package from the github, which is the case of the danparcorpR package, at the moment. So having the remotes package, you can install dancoprR package as the follows:
Note: Since it contains a bit of large text data inside it, installation may take a few minutes (less than 5 min usually) so just be patient until the below installation is completed :)
remotes::install_github("Peymankor/danparcorpR")
Now, the package should have been installed and it is ready to use.
Libraries
In our analysis in this blog, we will need the following four packages. I wrote small comments in front of them what they do,
Data Processing
Now, since in this specific analysis we are considering to analyze the data of whole 8 years (generally I do not recommend this one since data becomes so large on the memory, better use the subset of the data as much as possible, like corpus_2010)
Here, I am joining the tables together,
all_8_year <- rbind(corpus_2009, corpus_2010, corpus_2011, corpus_2012, corpus_2013,corpus_2014, corpus_2015, corpus_2016)
Here, we are converting the data to the tidy data. It means, each word of the tekst column will be one row, also we are removing the Parti with NA (which as I wrote in github Readme are the formand or Minister):
corpus_tidy_text <- all_8_year %>% select(Starttid, Parti, Tekst) %>% drop_na(Parti) %>% filter(Parti != "") %>% as_tibble() %>% unnest_tokens(word, Tekst)
So, after doing this, what we do is group the data with (half_year, word and Parti) and count them, using the tally function:
tidy_text_count <- corpus_tidy_text %>% group_by(half_year=round_date(Starttid, "halfyear"), word, Parti) %>% tally()
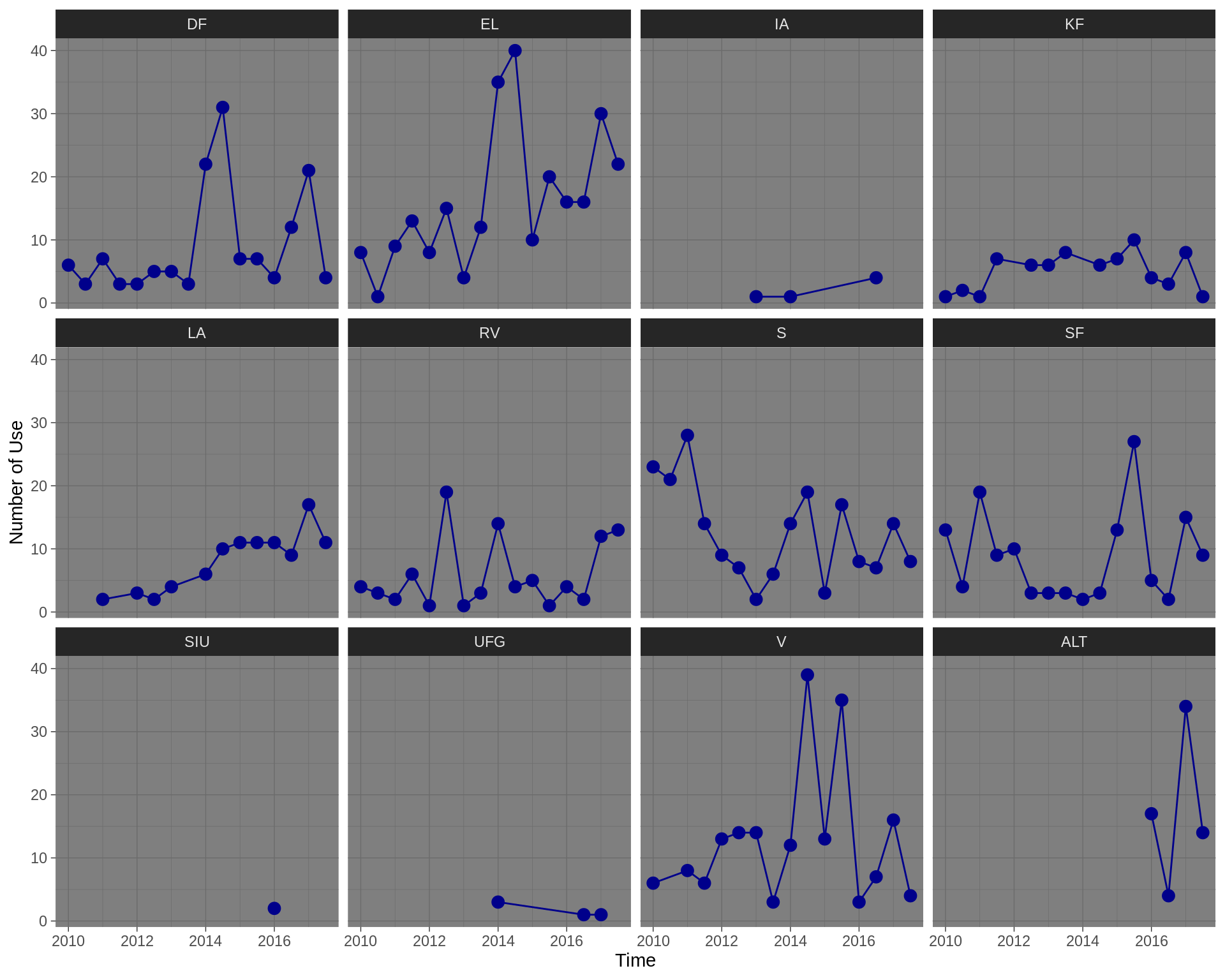
Usage of the Data Privacy Related Words in whole Parlimant, 2009-2017
So in the below, we are selecting the words we want to see how much they have been used over years. I I selected these words as the representative the Data Privacy topics, but it could be changed to any other combination:
datatilsynet,persondata,data,persondataloven, databeskyttelse,datasikkerhed,datasikkerheden
whole_parlimanet <- tidy_text_count %>% filter(word %in% c("datatilsynet","persondata","data", "persondataloven","databeskyttelse", "datasikkerhed", "datasikkerheden")) %>% group_by(half_year) %>% summarise(sum_use=sum(n)) #> `summarise()` ungrouping output (override with `.groups` argument)
The below plot shows number of the times the above 7 words has been mentioned in parlimant discussion, every half the year:
ggplot(whole_parlimanet, aes(half_year, sum_use)) + geom_point(size=5) + geom_smooth() + labs(x="Time", y = "Number of Use") #> `geom_smooth()` using method = 'loess' and formula 'y ~ x'
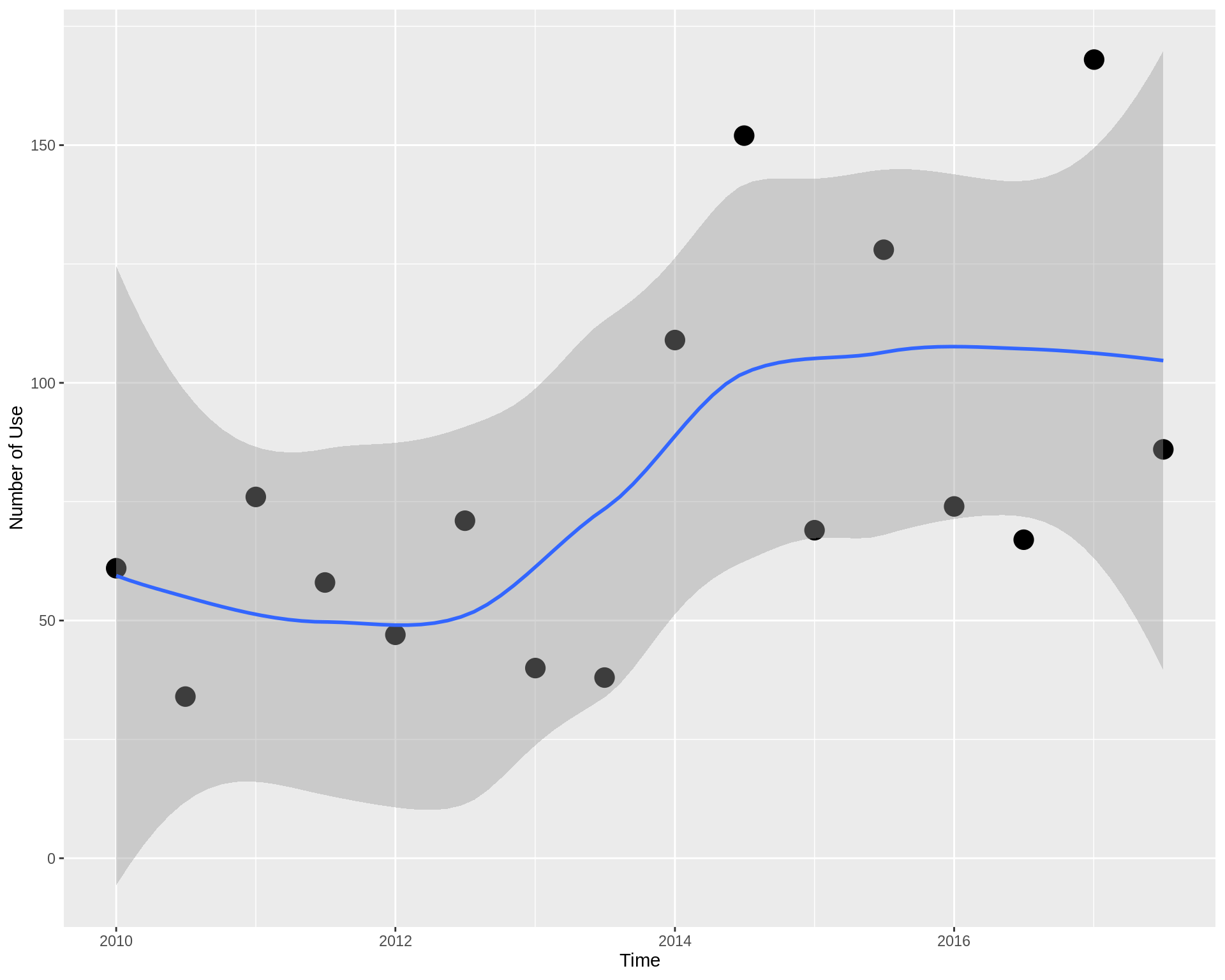
Usage of the Data Privacy Related Words in Parlimant per parti, 2009-2017
Now, here again we select the relevant words for the analysis, but this time we group by (half_year and parti) to see number of usage the words per each parti per half year period.
per_parti <- tidy_text_count %>% filter(word %in% c("datatilsynet","persondata","data", "persondataloven","databeskyttelse", "datasikkerhed", "datasikkerheden")) %>% group_by(half_year,Parti) %>% summarise(sum_use=sum(n)) #> `summarise()` regrouping output by 'half_year' (override with `.groups` argument)
ggplot(per_parti, aes(half_year, sum_use)) + geom_line(color="darkblue") + geom_point(color="darkblue", size=3) + facet_wrap(~ Parti) + labs(x="Time", y = "Number of Use") + theme_dark() #> geom_path: Each group consists of only one observation. Do you need to adjust #> the group aesthetic?